【デモ付き】OCR vs LLM OCRを徹底比較
既存システム連携まで見据えたLLM OCR導入の考え方
2026-02-20

目次
LLM OCRとは? これまでのOCRとの違い
これまでのOCRは、「画像に含まれる文字をテキストに変換する」ことを目的とした技術でした。主な役割は、スキャンした書類やPDFから文字列を抽出することで、あくまでも”文字を読み取る”ことに特化した仕組みでした。
一方、LLM OCRは画像を「見て」「理解」し、意味のある構造化データに変換します。
これにより、「この請求書の合計金額はいくら?」「契約書の解除条項はどこ?」といった質問に直接答えられるようになります。単なる文字認識ではなく、「理解して答える点」が最大の違いです。
名刺を例にすると、従来のOCRは全文テキストをそのまま出力するだけでしたが、LLM OCRは次のようなJSONを直接生成できます。
{
“company” : “AAA株式会社”
“部署”: “BBB部CCC”
”名前”: “ZZZ XXXX”
“電話番号” : “000-0000-0000”
“P”マーク” : true
}従来のOCRでは場所の指定や「株式会社」という文字を検索して会社名だと判別する必要がありましたが、LLM OCRの場合は、会社ごとのデザインの違いや項目の有無、追加情報などの違いを吸収することができます。
さらに、プロンプトも渡せることも大きな違いです。結果、出力形式や項目ごとの加工なども指定できるようにもなりました。
以上のことを表にまとめると、
| 観点 | 従来のOCR | LLM OCR |
| レイアウトの理解 | ほぼ不可能 | 表・段組み・注釈を理解可能 |
| 非定型の書類への対応 | 弱い | 強い |
| 追加の質問 | 不可 | 可能 |
| 出力形式 | 生テキスト | 指定可能・加工も可能 |
| 後処理 | ほぼ必須 | 要件に応じて |
なぜLLM OCRが注目されているのか
2025年以降、Gemini、GPT、ClaudeなどのマルチモーダルLLM(画像入力対応モデル)の進化が急速に進みました。従来の専用OCRエンジンと比べて、非定型文書・手書き・低品質画像への対応力が飛躍的に向上した結果、企業内に眠っている大量の紙の文書が低コストで価値のあるデータに変換できる可能性が出てきたのです。
例えば、
・紙の帳票
・PDFの請求書や契約書
・画像化された名刺や申込書
などです。これらは目視であれば理解できますが、従来のシステムでは扱いづらく、実質的に“死蔵データ”になっていました。
また、紙の文書を手入力でデータ化している企業も多くあると思います。これまで人手に依存していた業務の多くが、自動化の対象になるため注目されています。
なぜ今LLM OCRが必要なのか? どのような課題を解決できるのか?
LLM OCRの出現により、これまでのOCRはたくさんの課題があることが浮き彫りになりました。
その顕著な例を紹介します。
課題1:後処理の複雑さ
従来のOCRは「文字を読み取る」だけで、その後のデータ整形は別途開発が必要でした。
ここをワークフローで表すと、
画像 → OCR → 生テキスト → 正規表現 → データ整形 → バリデーション → 構造化して出力
となります。
LLM OCRの場合は、
画像 → LLM OCR(プロンプトで指示) → 構造化データ
となります。従来のOCRは工程も多かったことがわかります。
また、正規表現でデータを抜き出して整形しているため、そもそもの文字起こしをしたデータの精度が悪いと正規表現で抜き出せません。
そのため、結果的に出力されるデータが歯抜けだったり間違っていたりすることが往々にしてありました。
課題2:フォーマット依存
請求書という複雑な書類を例にします。
従来のOCRを使う場合には、取引先ごとに請求書のレイアウトが異なる場合、それぞれに対応したテンプレートや抽出ルールを作成する必要がありました。レイアウトが少し異なる場合であっても作成が必要であり、項目名が違う場合もルールを作らないといけませんでした。
このあたりの開発費用や保守費用は、運用する企業としてはとてもネックでした。
その点、LLM OCRは「請求金額」という概念を理解しているため、レイアウトが異なっていたとしても適切に情報を抽出できます。「Total」「合計」「請求額」「ご請求金額」など、表現が異なっていても同じ情報として認識できるのです。
結果、従来かかっていた費用は丸々なくなり、さらに柔軟に様々な書類に対応できるようになりました。
課題3:認識精度の限界
・手書き文字の認識率が低い
・表形式のデータ構造を維持できない
・スキャン品質が悪いと認識率が大幅に低下
従来のOCRは上記が問題で、認識の精度が低く、その後に続く加工処理にも影響がありました。LLM OCRではこれらの問題はほぼ解決しているのですが、精度問題については後ほど紹介します。
どのような場面に使えるのか? 具体的なユースケースをご紹介
この章では、OCRが使われていた場面やLLM OCRの登場によって業務効率が向上した事例などを紹介します。
- 請求書処理
従来のOCRでも実現可能ですが、LLM OCRにより会計システムの自動登録までも行うことができます。また過去データをいれることで、ミスなども検知することができます。 - 契約書管理
LLM OCRにより、柔軟な検索ができるようになります。
例えば「解約について教えて」と聞くと条件などを出力可能です。 - 名刺管理
展示会などで集めた名刺をそのままデータ化することができます。またLLMを組み合わせることによって、名刺情報をもとにWEB検索を行い、会社情報を自動で集めることもできます。 - 競合他社資料の分析
プレゼン資料やパンフレット・カタログなどから知りたい情報を抜き出して要約などをすることができます。 - 紙帳票のデータ化
- 医療・研究論文(専門文書の解析)
これらはあくまでも一例であり、他にもさまざまな事例があります。
従来OCRとの比較:精度・柔軟性・導入コストを徹底検証
これまでのOCRは精度がネックでしたが、LLM OCRにより精度の問題がほぼ解消しました。
そのため、処理速度と従量課金の予算が許されるのであればLLM OCRをAPI経由で使うのが一番良いと思います。
もし、システムの要件的に、精度がそこまで問題にならなければ、従量課金の必要のない従来のOCRを使用することで費用を安く抑えることができます。
| 項目 | 従来OCR | クラウドOCR | LLM OCR(GPT-4V、Claude等) |
| 文字認識精度 | 85〜90% | 90〜95% | 95〜99% |
| 手書き対応 | △(限定的) | ○(学習済みモデルなら対応) | ◎(高精度) |
| 表の構造維持 | × | △ | ◎ |
| 多言語混在 | △ | ○ | ◎ |
| レイアウト理解 | × | △ | ◎ |
| 構造化出力(JSON等) | ×(要開発) | △(一部対応) | ◎(プロンプトで指定) |
| 非定型フォーマット対応 | ×(テンプレート必須) | △ | ◎ |
| 導入コスト | 低(OSS) | 中 | 低 |
| 運用コスト(後処理開発含む) | 高 | 中 | 低〜中 |
| 処理速度 | 速い | 速い | やや遅い |
| API費用(1,000ページあたり) | ほぼ無料(サーバー費用のみ) | 約$1.50〜3.00 | 約$2〜10 |
※2026年2月時点
料金と費用対効果とシミュレーション(2026年2月時点)
パターン1:中小企業の経理部門(月500枚の請求書処理)
請求書の処理などを手入力している企業もまだまだあるかと思います。
LLM OCRを導入し、その作業を代替した場合
API費用:500枚 × $0.02 = $10(約1,500円)
確認作業:500枚 × 1分 = 約8時間
人件費:約20,000円/月
合計が約21,500円になります。
もし一人雇っている場合には、その差額がコストダウンになります。
使うLLM OCRのモデルにもよって料金は変動しますが、精度を担保できている最安のモデルを使うことで更に安く出来る可能性もあります。
【デモ】紹介
https://showcase.freshet.co.jp/ocr
こちらから試すことができます。
ログインが必要になるので、下記のアカウントをご利用ください(ログイン後の機能は同じです)。
- ID: demo_admin
- PW: DemoAdmin!2025
※送信されたデータはサーバーには保存されず、またAIの学習にも使われません。
使い方
ログインしている前提で進めます。
https://showcase.freshet.co.jp/ocr こちらにアクセス
- サンプル画像をダウンロードします。サンプル画像は名刺ですが、もし自社で読み込みをしてみたいデータがある場合にはそれを使用しても問題ありません。
※送信されたデータはサーバーには保存されず、またAIの学習にも使われません。
- 画像をアップロードの「ファイルを選択」を押して画像ファイルを選択します。
ファイルのプレビューが表示されるので確認します。
「OCRを実行」を押下することでOCRが開始されます。
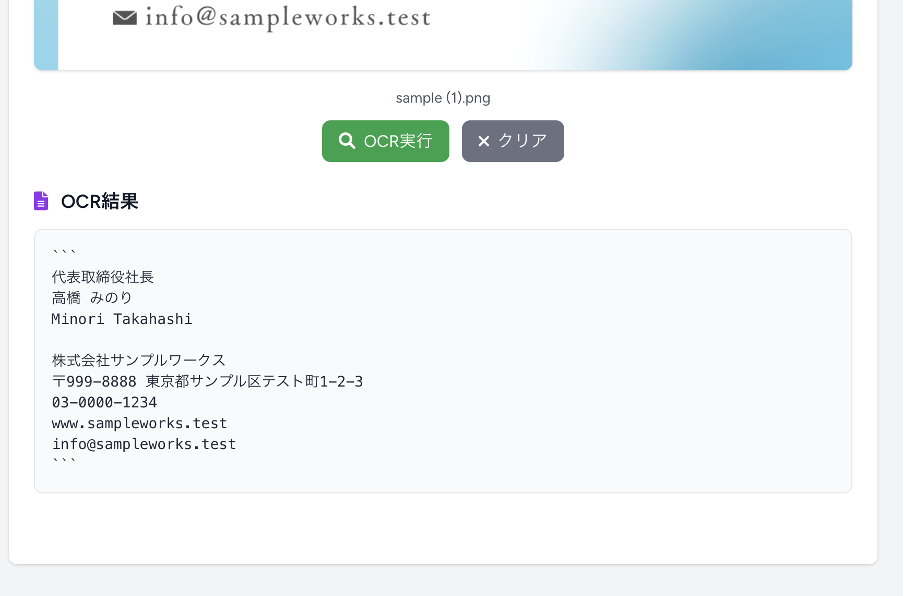
結果が表示されます。
ほぼ全ての文字がしっかり認識されているでしょうか?
さらにプロンプトで特定の部分だけ抜き出したり、後続の処理に渡しやすいようにJSONなどの構造化されたデータを出力したりすることも可能です。
是非手元にある画像などを入れてみてください。
LLM OCRに関するよくある質問
Q1. 手書き文字も認識できますか?
最新のLLM OCRは手書き文字にも対応しています。極端に崩れた文字や特殊な筆跡は認識精度が下がる場合がありますが、手書きでも一定の精度が期待できます。
Q2. どの言語に対応していますか?
主要なLLM(GPT-4V、Claude、Gemini)は、日本語を含む100以上の言語に対応しています。日本語と英語が混在した文書も問題なく処理できます。
Q3. PDFも処理できますか?
PDFファイルも処理可能です。テキスト埋め込みPDF、スキャンPDF(画像PDF)のどちらにも対応しています。
Q4. 処理できる文書のサイズに制限はありますか?
各APIには入力サイズの制限があります。一般的に1ページあたり数MBまで対応していますが、大きなファイルは分割して処理することを推奨します。
Q5. オフラインで使用できますか?
クラウドAPIを利用する場合はインターネット接続が必要です。オフライン環境では、ローカルデプロイ可能なオープンソースモデルを検討してください。
Q6. 既存システムとの連携は可能ですか?
REST APIとして提供されているため、ほとんどのシステムと連携可能です。会計ソフト、CRM、ERPなどとの連携実績があります。
Q7. 無料で試せますか?
多くのプロバイダーが無料枠を提供しています。また、当社のデモサイトでも無料でお試しいただけます。
Q8. 導入にどのくらい時間がかかりますか?
シンプルな用途であれば、数日で利用開始可能です。既存システムとの連携やカスタマイズが必要な場合は、2~4週間程度を見込むとよいでしょう。
Q9. 小規模でも導入価値はありますか?
月数百枚規模であっても、人手削減効果が上回るケースが多いです。
さいごに
LLM OCRは、単体で導入するだけでは本当の価値を発揮しません。重要なのは、読み取ったデータをどの業務にどうつなぎ、どこまで自動化し、どの工程を人が確認するのかまでを設計することです。請求書処理、契約管理、名刺情報の活用など、既存システムとの連携や社内フローへの組み込みまで踏み込んで初めて、投資対効果は最大化されます。
フレシット株式会社は、LLM OCRの技術検証だけでなく、その先の会計システム連携、CRM連動、承認フロー統合まで含めたフルスクラッチ開発を得意としています。既存パッケージに業務を合わせるのではなく、貴社の業務に合わせて最適な形で設計し、実装し、運用まで伴走します。
「OCRを試してみたい」ではなく、「業務を変えたい」とお考えであれば、ぜひ一度ご相談ください。貴社専用のオーダーメイドシステムとして、LLM OCRの可能性を最大限引き出します。
>>フルスクラッチ(オーダーメイド)のシステム開発について詳細はこちら
著者プロフィール
フレシット株式会社 代表取締役 増田順一
柔軟な発想でシステム開発を通して、お客さまのビジネスを大きく前進させていくパートナー。さまざまな業界・業種・企業規模のお客さまの業務システムからWEBサービスまで、多岐にわたるシステムの開発を手がける。一からのシステム開発だけでは無く、炎上案件や引継ぎ案件の経験も豊富。システム開発の最後の砦、殿(しんがり)。システム開発の敗戦処理のエキスパート。

公式Xアカウントはこちら

